2026
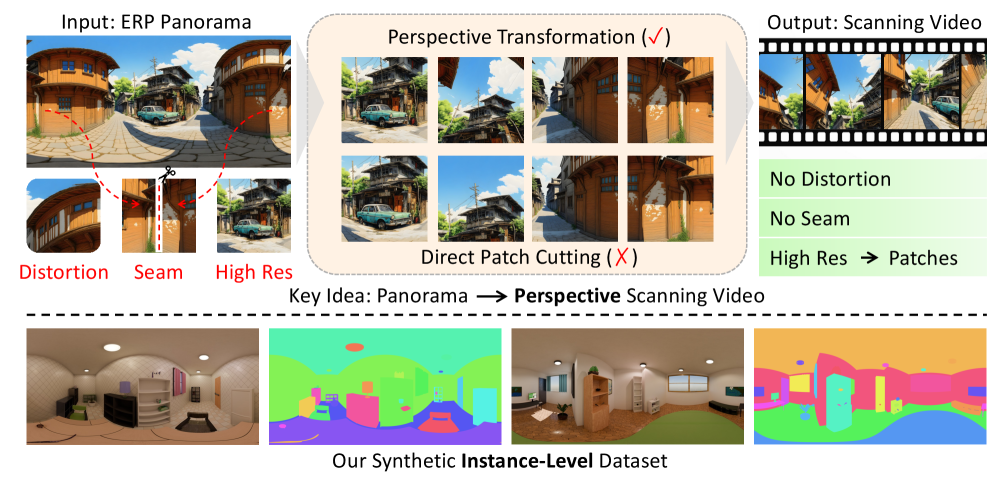
SAP: Segment Any 4K Panorama
Lutao Jiang, Zidong Cao, Weikai Chen, Xu Zheng, Yuanhuiyi Lyu, Zhenyang Li, Zeyu Hu, Yingda Yin, Keyang Luo, Runze Zhang, Kai Yan, Shengju Qian, Haidi Fan, Yifan Peng, Xin Wang, Hui Xiong, Ying-Cong Chen
Preprint 2026
SAP: Segment Any 4K Panorama
Lutao Jiang, Zidong Cao, Weikai Chen, Xu Zheng, Yuanhuiyi Lyu, Zhenyang Li, Zeyu Hu, Yingda Yin, Keyang Luo, Runze Zhang, Kai Yan, Shengju Qian, Haidi Fan, Yifan Peng, Xin Wang, Hui Xiong, Ying-Cong Chen
Preprint 2026

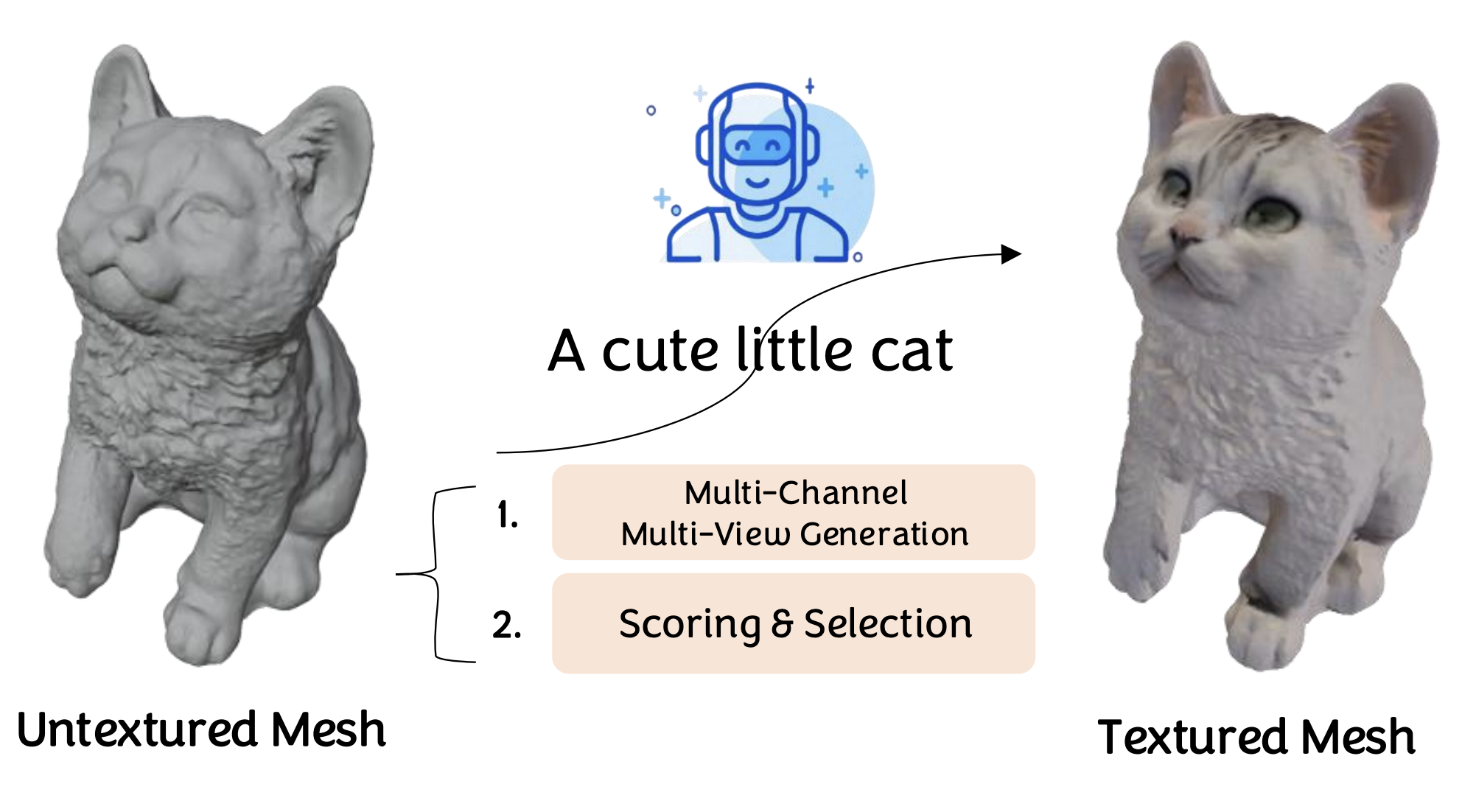
MuMA: 3D PBR Texturing via Multi-Channel Multi-View Generation and Agentic Post-Processing
Lingting Zhu, Jingrui Ye, Runze Zhang, Zeyu Hu, Yingda Yin, Lanjiong Li, Jinnan Chen, Shengju Qian, Xin Wang, Qingmin Liao, Lequan Yu
TIP 2026 (accepted)
MuMA: 3D PBR Texturing via Multi-Channel Multi-View Generation and Agentic Post-Processing
Lingting Zhu, Jingrui Ye, Runze Zhang, Zeyu Hu, Yingda Yin, Lanjiong Li, Jinnan Chen, Shengju Qian, Xin Wang, Qingmin Liao, Lequan Yu
TIP 2026 (accepted)
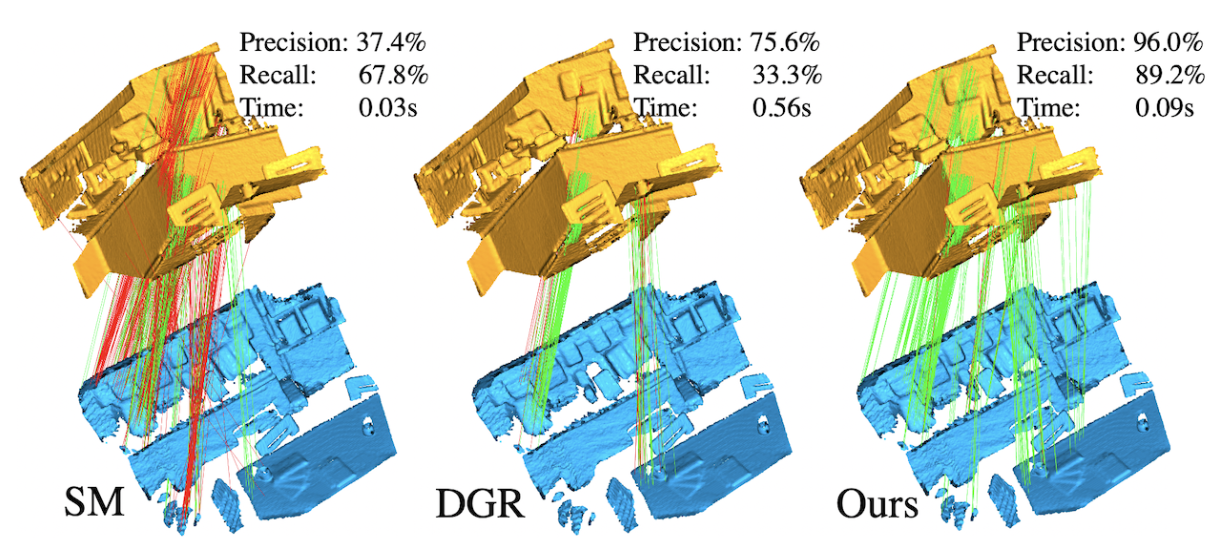
WGS: Watertight Geometry Standardization for Scalable 3D Generation
Dehao Hao, Tanghui Jia, Kaiyi Zhang, Weikai Chen, Zeyu Hu, Yingda Yin, Runze Zhang, Lingting Zhu, Li Yuan, Xin Wang, Long Quan
CVPR 2026
WGS: Watertight Geometry Standardization for Scalable 3D Generation
Dehao Hao, Tanghui Jia, Kaiyi Zhang, Weikai Chen, Zeyu Hu, Yingda Yin, Runze Zhang, Lingting Zhu, Li Yuan, Xin Wang, Long Quan
CVPR 2026
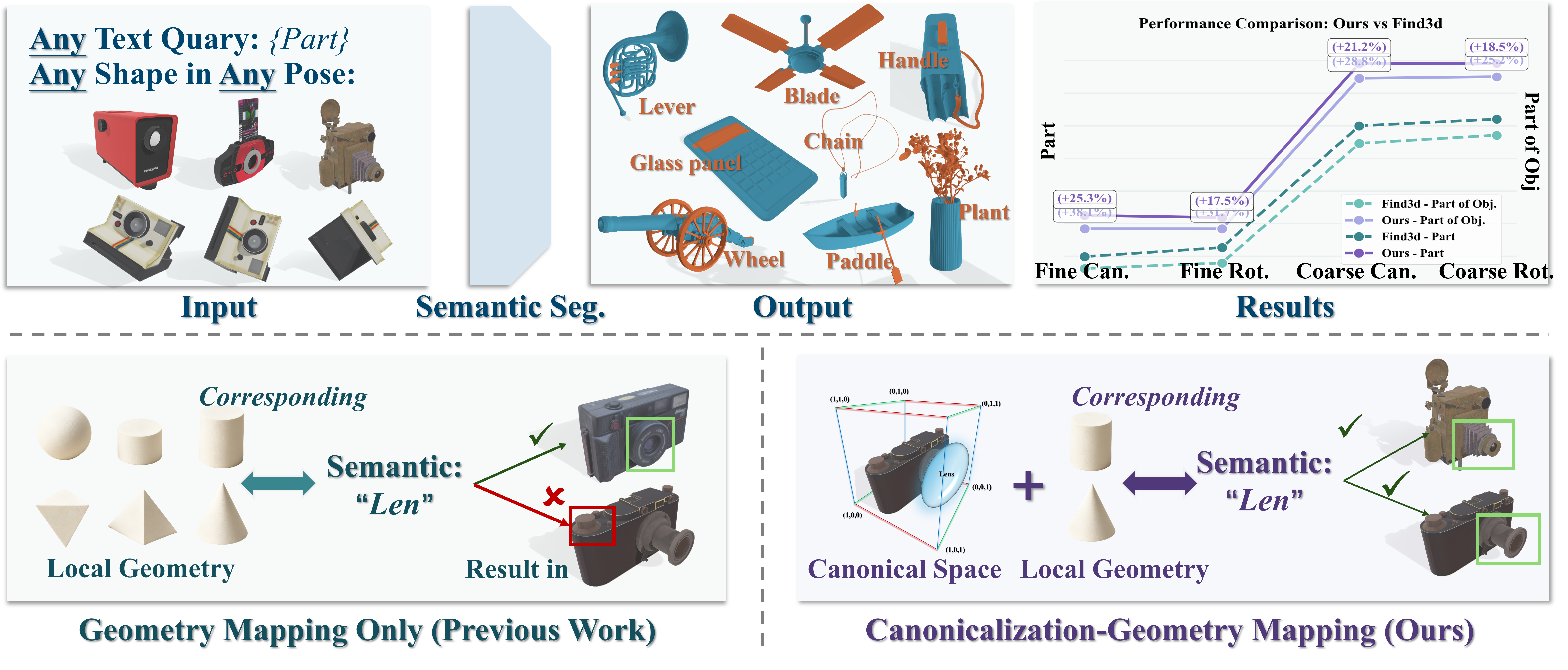
CoSMo3D: Open-World Promptable 3D Semantic Part Segmentation through LLM-Guided Canonical Spatial Modeling
Li Jin, Weikai Chen, Yujie Wang, Yingda Yin, Zeyu Hu, Runze Zhang, Keyang Luo, Shengju Qian, Xin Wang, Xueying Qin
CVPR 2026 Oral
CoSMo3D: Open-World Promptable 3D Semantic Part Segmentation through LLM-Guided Canonical Spatial Modeling
Li Jin, Weikai Chen, Yujie Wang, Yingda Yin, Zeyu Hu, Runze Zhang, Keyang Luo, Shengju Qian, Xin Wang, Xueying Qin
CVPR 2026 Oral


2025

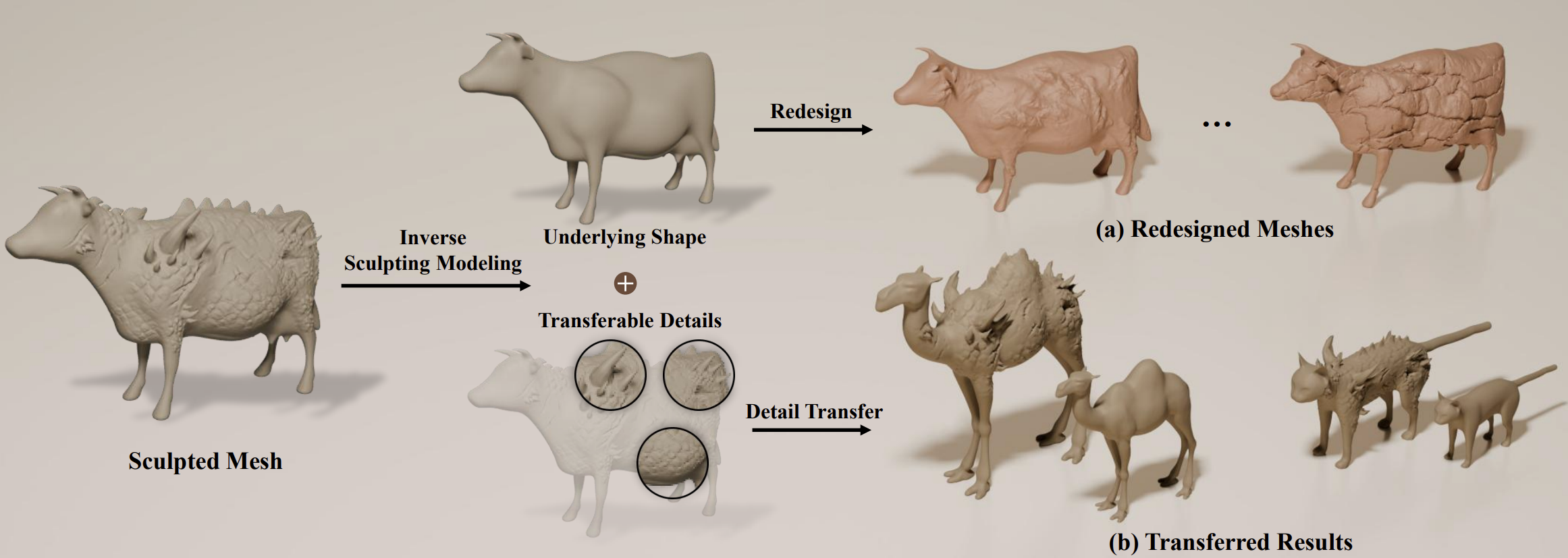
Light-SQ: Structure-aware Shape Abstraction with Superquadrics for Generated Meshes
Yuhan Wang, Weikai Chen, Zeyu Hu, Runze Zhang, Yingda Yin, Ruoyu Wu, Keyang Luo, Shengju Qian, Yiyan Ma, Hongyi Li, Yuan Gao, Yuhuan Zhou, Hao Luo, Wan Wang, Xiaobin Shen, Zhaowei Li, Kuixin Zhu, Chuanlang Hong, Yueyue Wang, Lijie Feng, Xin Wang, Chen Change Loy
SIGGRAPH Asia 2025
Light-SQ: Structure-aware Shape Abstraction with Superquadrics for Generated Meshes
Yuhan Wang, Weikai Chen, Zeyu Hu, Runze Zhang, Yingda Yin, Ruoyu Wu, Keyang Luo, Shengju Qian, Yiyan Ma, Hongyi Li, Yuan Gao, Yuhuan Zhou, Hao Luo, Wan Wang, Xiaobin Shen, Zhaowei Li, Kuixin Zhu, Chuanlang Hong, Yueyue Wang, Lijie Feng, Xin Wang, Chen Change Loy
SIGGRAPH Asia 2025


Large Material Gaussian Model for Relightable 3D Generation
Jingrui Ye, Lingting Zhu, Runze Zhang, Zeyu Hu, Yingda Yin, Lanjiong Li, Lequan Yu, Qingmin Liao
Preprint 2025
Large Material Gaussian Model for Relightable 3D Generation
Jingrui Ye, Lingting Zhu, Runze Zhang, Zeyu Hu, Yingda Yin, Lanjiong Li, Lequan Yu, Qingmin Liao
Preprint 2025

2024
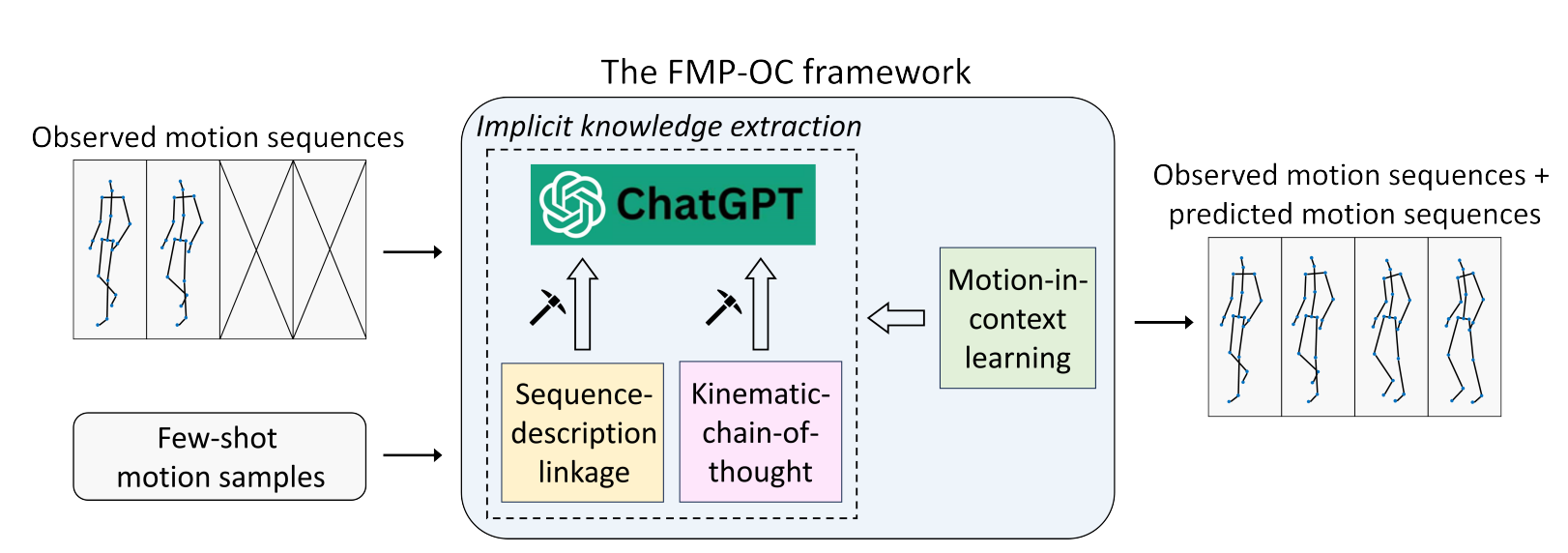
Off-the-shelf ChatGPT is a Good Few-shot Human Motion Predictor
Haoxuan Qu, Zhaoyang He, Zeyu Hu, Yujun Cai, Jun Liu
Preprint 2024
Off-the-shelf ChatGPT is a Good Few-shot Human Motion Predictor
Haoxuan Qu, Zhaoyang He, Zeyu Hu, Yujun Cai, Jun Liu
Preprint 2024